- TLDR AI
- Posts
- China Drops a DIY GPT-4 Killer
China Drops a DIY GPT-4 Killer
PLUS: H20 shipments resume and Teslas get their own co-pilot
Helena Liu
July 15, 2025
Good morning, AI enthusiasts. China’s Moonshot AI just open-sourced a 1-trillion-parameter model that claims GPT-4-level coding skill, Washington quietly re-opened the GPU tap for Nvidia’s Chinese customers, and every new Tesla now chats back with Grok 4. To close things out, DeepMind open-sourced a library that turns messy multimodal workflows into snap-together bricks.
In today’s TLDR AI:
Moonshot debuts Kimi-K2, a free 1-trillion-parameter MoE that scores at or above GPT-4 on coding and math tests
Nvidia resumes H20 chip shipments to China and unveils an export-friendly RTX Pro GPU
Tesla’s 2025.26 software update adds Grok 4 voice chat to every new vehicle
DeepMind releases GenAI Processors, an open-source Python library for no-friction, parallel AI pipelines
LATEST DEVELOPMENTS
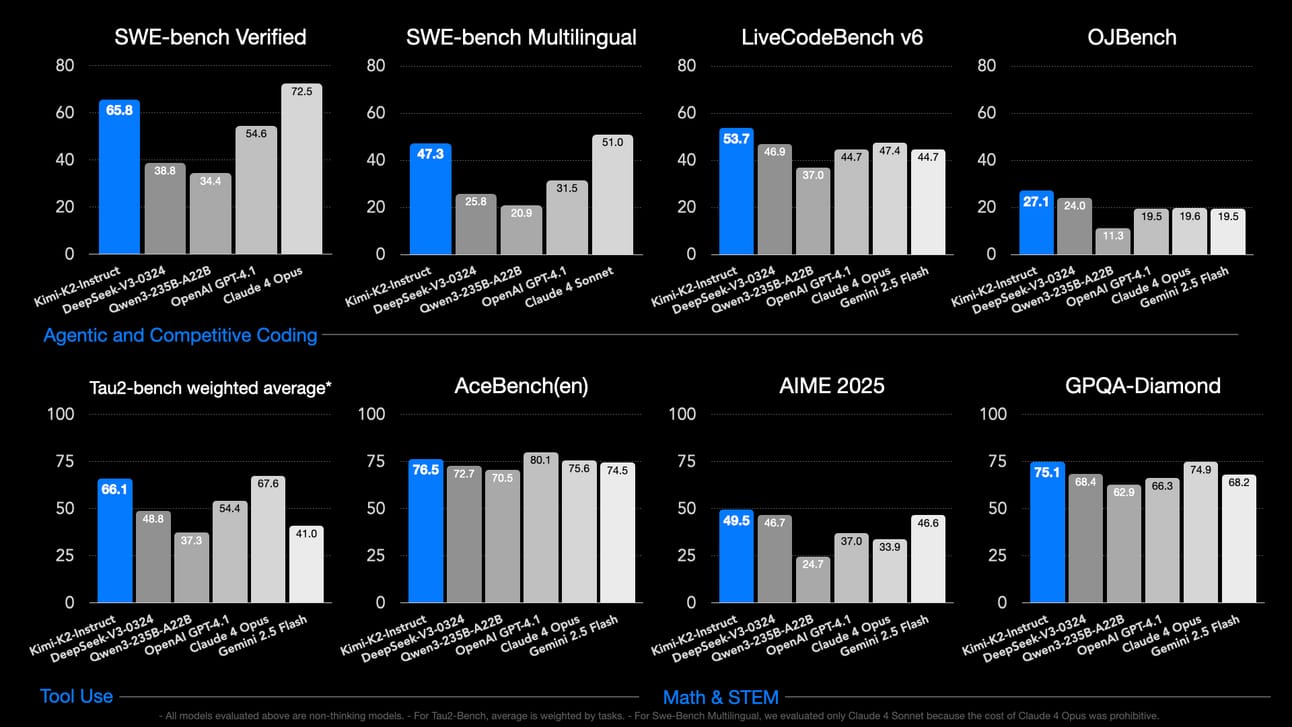
TLDR: A Chinese startup has open-sourced Kimi-K2, a mixture-of-experts model that uses 1 trillion total parameters (32 billion active) and outperforms GPT-4 on several coding and math benchmarks.
The team trained K2 on 15.5 trillion tokens including 400 billion lines of code and stabilised it with a custom “Muon” optimiser.
K2 can handle 128 k-token prompts, which means it can ingest two full PhD theses and still answer coherently.
Inference costs stay near those of Llama-3-70B because the model activates only 32 billion parameters at runtime.
Moonshot released both a base version for fine-tuning and an instruct version for drop-in chat, all under an Apache-2 licence.
Why it matters: Open-weights models just leapt from 70 billion to 1 trillion parameters, pushing the open-source ceiling higher and turning up the heat on U.S. export controls.

TLDR: U.S. regulators have re-approved H20 accelerator sales to China, and Nvidia introduced a trimmed “RTX Pro” Blackwell GPU that slides under the latest export caps.
The renewed licence frees roughly $4.5 billion worth of H20 inventory that had been stuck in warehouses for three months.
RTX Pro keeps Blackwell cores but limits NVLink bandwidth to 400 GB/s so it stays below the FLOP-per-watt threshold in U.S. rules.
Jensen Huang told customers in Beijing that “civil AI runs best on U.S. silicon,” subtly nudging them away from Huawei Ascend chips.
Analysts note that Chinese cloud providers still rely on Nvidia for more than 60 percent of their high-end AI compute.
Why it matters: Even as domestic GPUs mature, China’s biggest labs still queue for Nvidia hardware, underscoring both the leverage and the fragility of American chip dominance.

TLDR: Software update 2025.26 installs xAI’s voice assistant in all Teslas delivered after 12 July, and older Ryzen-equipped cars can opt-in.
Drivers activate Grok by holding the steering-wheel scroll wheel, then choose between “Default,” “Storyteller,” or a cheeky “Unhinged” persona.
Spoken queries travel to xAI servers where they are anonymised for privacy but retained to fine-tune future model versions.
Early users report that Grok summarises trips, delivers roadside trivia and cracks the occasional dad joke, though it still avoids direct driving commands.
Elon Musk says European and Asia-Pacific roll-outs will follow once new language packs pass in-car validation later this year.
Why it matters: Full self-driving remains elusive, so Tesla is keeping owners engaged and harvesting millions of real-world prompts through an ever-smarter in-car chatbot.

TLDR: Google DeepMind has released an MIT-licensed Python library that lets developers chain or parallelise modular “processors” for real-time, multimodal workloads without Ray or Airflow.
The starter kit ships with wrappers for Gemini text-and-vision models, live video streams and on-device inference, so basic pipelines spin up in a handful of lines.
Internal benchmarks show a two-to-three-times throughput boost on video-caption jobs thanks to asynchronous queue pooling.
Each processor checkpoints its state, retries on failure and passes artefacts with type-safe validation, keeping long pipelines resilient.
DeepMind designed the framework to dovetail with the upcoming Gemini-3 tool-calling API, hoping it will become the standard rails for agent workflows.
Why it matters: Powerful models are pointless if the glue code is brittle; an open, Google-backed orchestration layer could become the backbone of production-grade AI systems.
COMMUNITY
Want to master AI & automations? Ready to turn your AI skills into a new revenue stream? Get started with our FREE workshop.

Learn how you can monetize AI and get certified as an AI specialist during our free web class. Click here to register.
Reply